ABSTRACT
A Trie (derived from “retrieval”) is a tree structure designed to store a set of strings. Unlike standard Binary Search Trees, the keys are not stored within the nodes themselves; instead, a key is defined by the concatenation of labels along the path from the root to a specific node.
1. Structural Properties
The Multiway Trie expands the concept of a Binary Trie to support any alphabet (e.g., English letters, DNA bases, or digits).
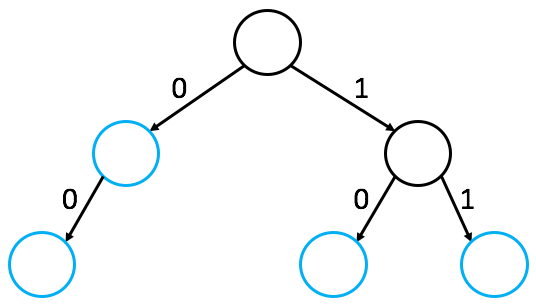
- Edge Labels: Characters are assigned to edges, not nodes.
- Word Nodes: Since a path can represent a prefix that isn’t a full word (e.g., “ca” is a prefix for “car”), specific nodes are marked to indicate the end of a valid word. In diagrams, these are often highlighted as blue nodes.
- The Root: An empty Trie consists of a single root node with no outgoing edges. The root represents an empty string.
2. Core Operations
Multiway Tries provide highly efficient operations based on the length of the string () rather than the number of items ().
Find
To find a word, start at the root and follow the edges corresponding to each character in the string.
- Success: You traverse all characters and land on a marked word node.
- Failure: You hit a “null” edge (the path doesn’t exist) or the final node is not marked as a word node.
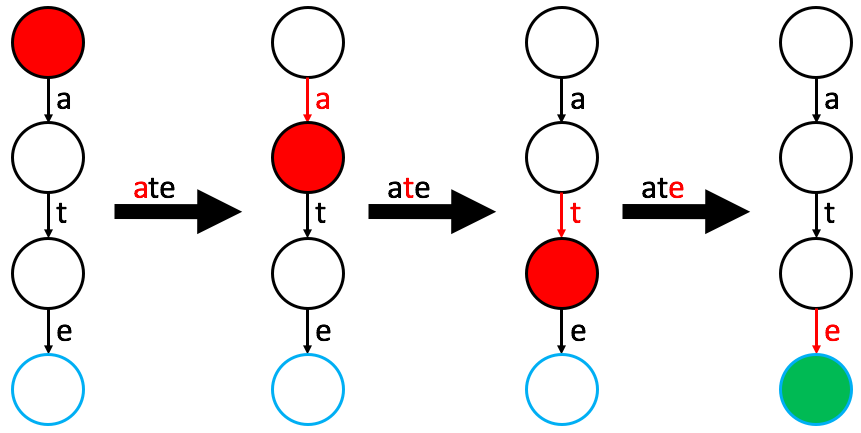
find(word): // find word in this Multiway Trie
curr = root
for each character c in word:
if curr does not have an outgoing edge labeled by c:
return False
else:
curr = child of curr along edge labeled by c
if curr is a word-node:
return True
else:
return FalseInsert
- Traverse the path for the word.
- If an edge for the next character is missing, create a new node and edge.
- Once the end of the word is reached, label the final node as a word node.
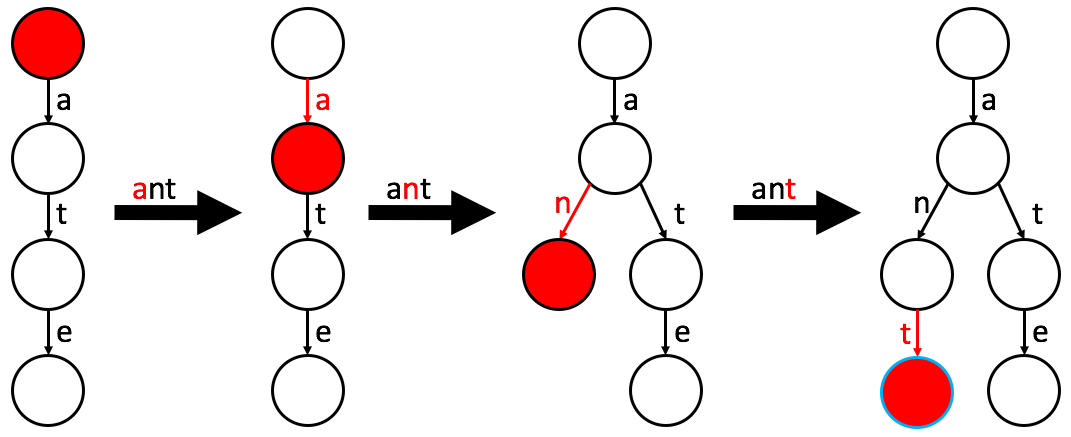
insert(word): // insert word into this Multiway Trie
curr = root
for each character c in word:
if curr does not have an outgoing edge labeled by c:
create a new child of curr with the edge labeled by c
curr = child of curr along edge labeled by c
if curr is not a word-node:
label curr as a word-nodeEdges, Not Nodes!
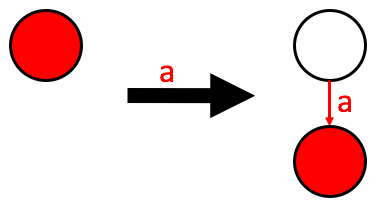
In a Multiway Trie, characters label the edges, not the nodes themselves. This is a common point of confusion during implementation.
An Empty Trie: Consists of a single root node with no outgoing edges.
A Single-Letter Insertion: If you insert the word “a”, you must create a second node. The character “a” serves as the label for the edge connecting the root to this new child node.
Remove
- Locate the word using the
findlogic. - If found, simply remove the word node label.
NOTE
The nodes and edges typically remain to support other words that share that prefix
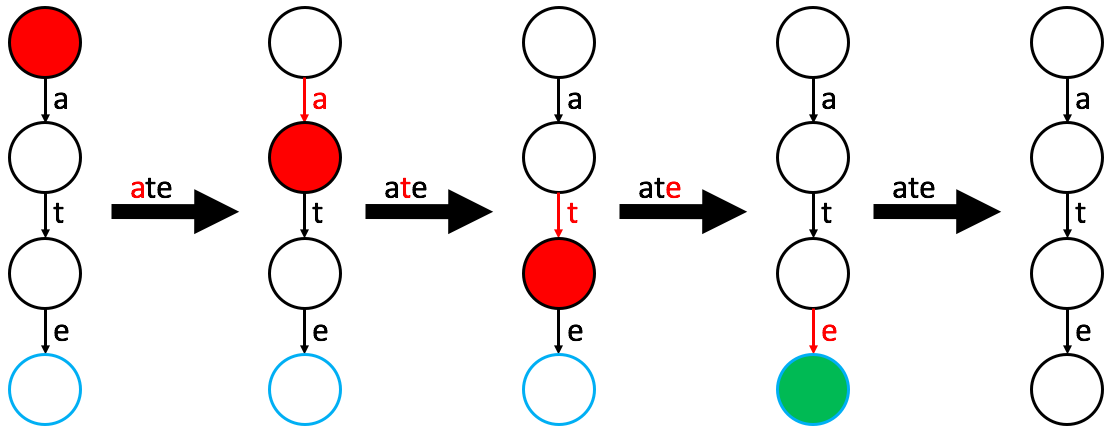
remove(word): // remove word from this Multiway Trie
curr = root
for each character c in word:
if curr does not have an outgoing edge labeled by c:
return
else:
curr = child of curr along edge labeled by c
if curr is a word-node:
remove the word-node label of curr3. Physical Implementation: The Array Strategy
To ensure that each character transition is as fast as possible, Multiway Tries prioritize speed over memory efficiency.
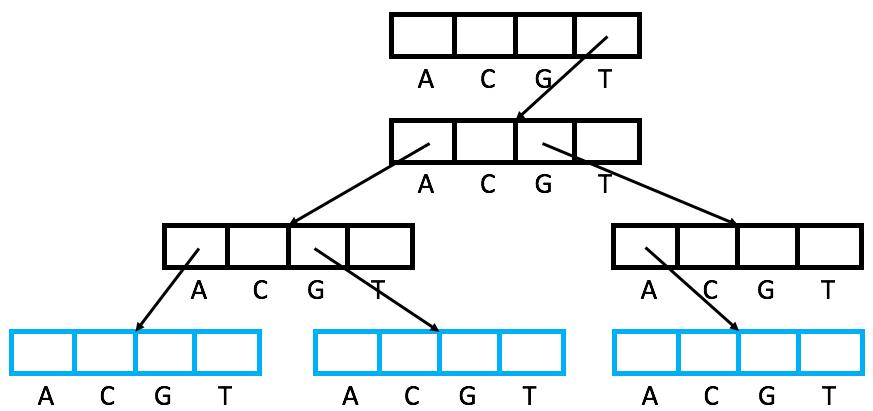
- The Node Array: Every node contains an array of pointers equal to the size of the alphabet (). For the English alphabet, each node has 26 slots.
- Access: Because each character maps directly to an array index (e.g., ‘a’ 0, ‘b’ 1), the time to follow an edge is constant.
- Complexity: This results in a worst-case time complexity of for search, insert, and remove.
4. Alphabetical Iteration and Auto-complete
Because a Multiway Trie is naturally organized by character, it is inherently sorted. This allows us to perform operations that are impossible in an unordered structure like a Hash Table.
Alphabetical Iteration
By performing a recursive traversal, we can output all words in the lexicon in perfect alphabetical order.
- Ascending Order: Use a Pre-order Traversal. We check if the current node is a “word-node” first, then visit the children in alphabetical order (e.g., ‘a’ through ‘z’).
- Descending Order: Use a Post-order Traversal. We visit the children in reverse alphabetical order (e.g., ‘z’ through ‘a’) before checking the current node.
ascendingPreOrder(node): // Output words in ascending order
if node is a word-node:
output the word labeled by path from root to node
for each child of node (in ascending order):
ascendingPreOrder(child)
descendingPostOrder(node): // Output words in descending order
for each child of node (in descending order):
descendingPostOrder(child)
if node is a word-node:
output the word labeled by path from root to nodeAuto-complete (Prefix Search)
The Trie is often called a Prefix Tree because every node represents a prefix shared by all its descendants. This makes “Auto-complete” highly efficient:
- Traverse to Prefix: Start at the root and follow the edges for the given prefix (e.g., “cat”).
- Subtree Search: Once you reach the node representing that prefix, perform a
ascendingPreOrdertraversal on that specific subtree. - Result: This will output every word in the Trie that begins with those characters.
5. Strengths and Weaknesses
Advantages
- Deterministic Speed: Performance depends only on the length of the word (), not the total number of words ().
- Alphabetical Ordering: A Pre-order Traversal of the trie visits nodes in alphabetical order.
- Prefix Matching: Tries are uniquely suited for Auto-complete features, as all words sharing a prefix are grouped under the same subtree.
Disadvantages
- Space Inefficiency: This is the primary drawback. Because every node allocates space for an entire alphabet’s worth of pointers, a “sparse” trie (one where many characters don’t follow others) wastes a significant amount of memory on
NULLpointers.