ABSTRACT
A Multiway Trie (or Prefix Tree) is a data structure designed specifically for storing sets of strings. It achieves a worst-case time complexity of for lookups, where is the length of the word, while maintaining alphabetical ordering—a feat that Hash Tables cannot match.
1. Mechanics: The Path-to-Word Mapping
In a Lexicon implemented via a Multiway Trie, words are not stored as single values within nodes. Instead, they are represented by the edges traversed from the root:
- Traversal: To find a word, the system follows the edges labeled with the word’s characters in sequence.
- Validation: A word is only considered “in the lexicon” if the traversal ends at a node explicitly marked as a word-node.
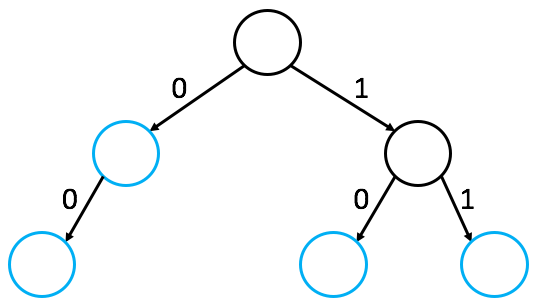
Edges, Not Nodes! In a Multiway Trie, letters label the edges, not the nodes.
- An empty trie is a single root node with no edges.
- Inserting a single-letter word like “a” requires creating a second node so the character “a” can label the connecting edge.
2. Performance Analysis
find(word)
Complexity:
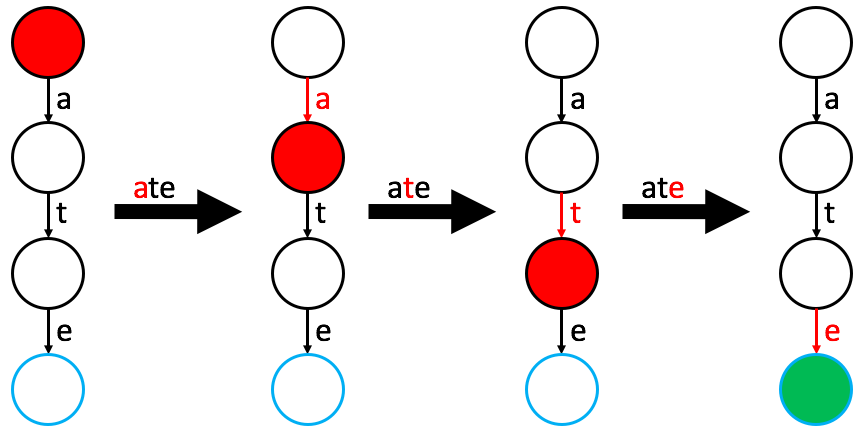
To find a word, start at the root and, for each letter of the word, follow the corresponding edge of the current node.
- Failure (Missing Edge): If the edge you need to traverse does not exist, the word is not in the trie.
- Failure (Not a Word Node): Even if the path exists, if the final node reached is not labeled as a “word node,” the word does not exist in the trie (it is merely a prefix of another word).
- Success: A word only exists if you traverse all required edges and land on a labeled word node.
find(word): // find word in this Multiway Trie
curr = root
for each character c in word:
if curr does not have an outgoing edge labeled by c:
return False
else:
curr = child of curr along edge labeled by c
if curr is a word-node:
return True
else:
return Falseinsert(word)
Complexity:
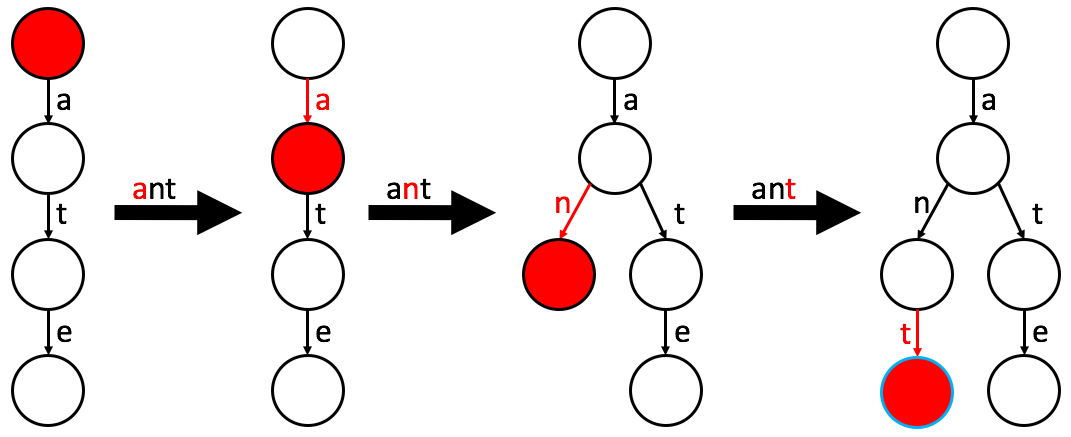
The insertion algorithm attempts to follow the find logic but builds the path where it is missing.
- Start at the root and attempt to follow edges for each character in the word.
- Create Missing Edges: If at any point the required edge does not exist, create the edge and the node it points to.
- Label Final Node: Once the end of the word is reached, label the final node as a word node.
insert(word): // insert word into this Multiway Trie
curr = root
for each character c in word:
if curr does not have an outgoing edge labeled by c:
create a new child of curr with the edge labeled by c
curr = child of curr along edge labeled by c
if curr is not a word-node:
label curr as a word-noderemove(word)
Complexity:
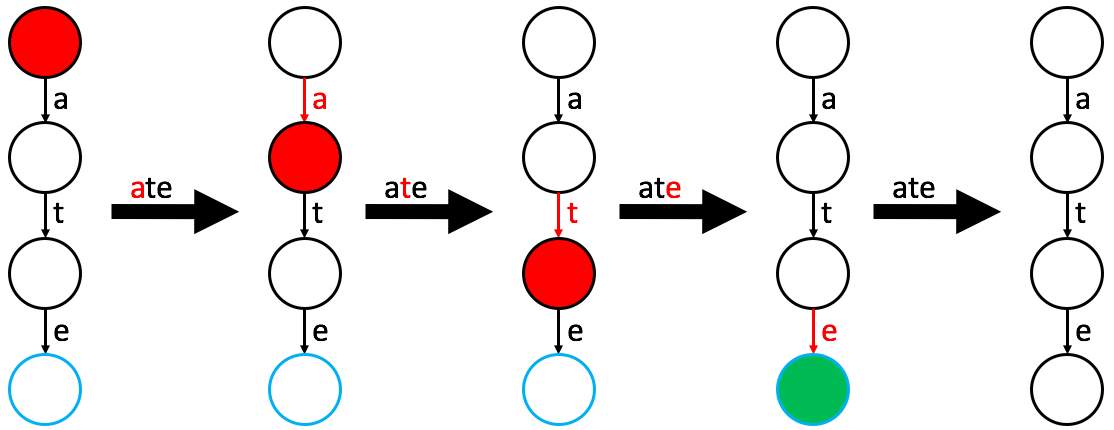
Removing a word is essentially a find operation followed by an unmarking step.
- Follow the
findalgorithm to locate the word’s terminal node. - If the word is not found, no action is needed.
- If found, simply remove the “word node” label from that node. The path remains to preserve other words that may share those prefixes.
remove(word): // remove word from this Multiway Trie
curr = root
for each character c in word:
if curr does not have an outgoing edge labeled by c:
return
else:
curr = child of curr along edge labeled by c
if curr is a word-node:
remove the word-node label of currSpace Complexity
Complexity:
To maintain access to each child during traversal, nodes typically use an array of size (the alphabet size). While fast, this is memory-inefficient as many slots remain empty.
3. Advanced Lexicon Features
The hierarchical structure of the Trie enables features essential for modern digital dictionaries.
- Alphabetical Iteration: By performing a Pre-order Traversal (visiting children in alphabetical order), the entire lexicon can be printed in sorted order.
- Auto-complete: By traversing to a specific prefix node (e.g., “cat”) and then performing a traversal on its subtree, the system can instantly retrieve all words starting with that prefix (e.g., “cats”, “catnip”, “cathedral”).
4. Evaluation for Lexicon ADT
While the Multiway Trie is incredibly fast, it is often criticized for its memory consumption:
- Speed: It offers worst-case speed. Unlike Hash Tables, there is no risk of collisions degrading performance to .
- Ordering: It is superior to Hash Tables for tasks requiring alphabetical order or prefix matching.
- Memory Waste: This is the primary drawback. Each node stores an array of pointers (e.g., 26 for English). If the trie is sparse, most of these pointers are
NULL, leading to significant space inefficiency.
5. Comparison: Hash Table vs. Multiway Trie
| Feature | Hash Table (Average) | Multiway Trie (Worst-Case) |
|---|---|---|
| Search Speed | ||
| Alphabetical Order | No | Yes |
| Auto-complete | No | Yes |
| Space Efficiency | Moderate () | Low (Wasted array slots) |
| Deterministic | No (Average-case focus) | Yes (Strictly ) |