ABSTRACT
Huffman coding is a variable-length, prefix-free encoding scheme. It achieves data compression by assigning shorter bitstrings to more frequent symbols and longer bitstrings to less frequent ones. It is mathematically proven to be an optimal character-by-character encoding method.
The Core Concept
Unlike Fixed Length CBC, where every character is taxed the same amount of bits, Huffman coding is adaptive. It minimizes the total weighted path length of a binary tree, where weights represent character frequencies.
Key Properties
- Prefix-Free: No codeword is a prefix of any other codeword (e.g., if ‘A’ is
01, no other character can start with01). This makes the code comma-free or self-delimiting. - Greedy Approach: The algorithm builds the tree from the “bottom up” by repeatedly merging the two least frequent nodes.

Building a Huffman Tree: Step-by-Step
1. Initialize and Sort
List all characters and their frequencies. Sort them in decreasing order. If frequencies are tied, use alphabetical order as a tie-breaker.
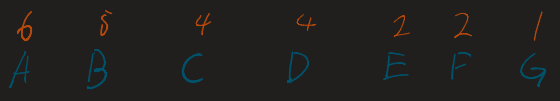
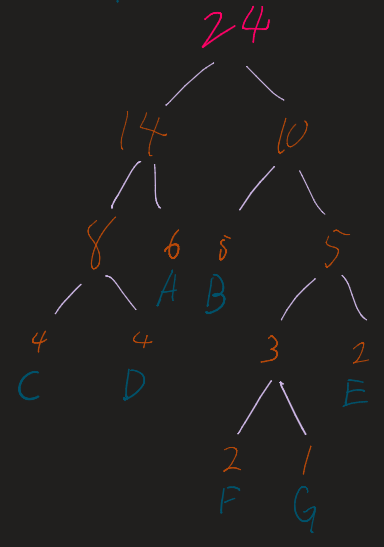
2. The Merge Loop
Repeat the following until only one tree (the root) remains:
- Take the two nodes with the lowest frequencies.
- Combine them into a new internal node.
- The frequency of the new node is the sum of the two children.
- Re-insert this new node into the list and re-sort.
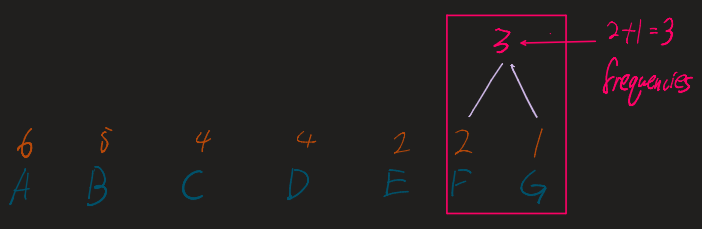
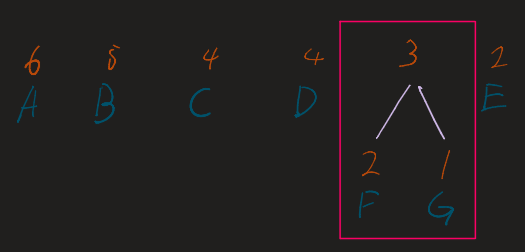
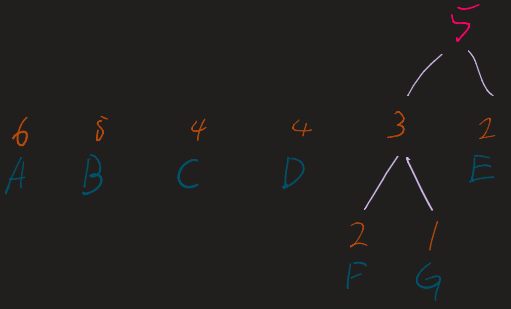
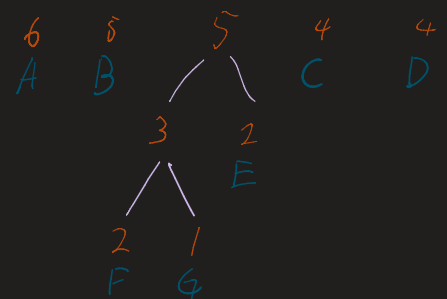
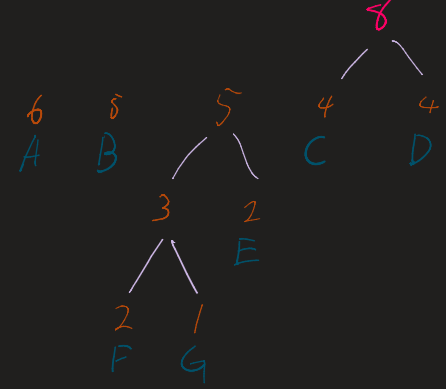
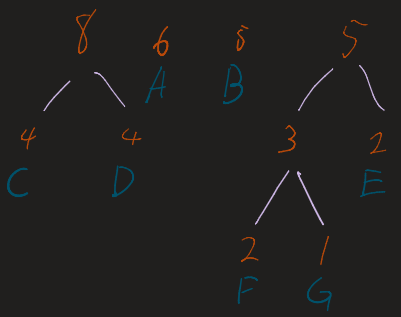
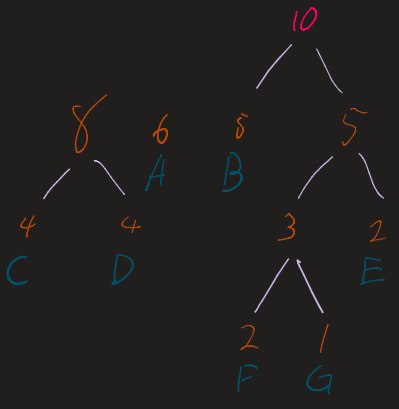
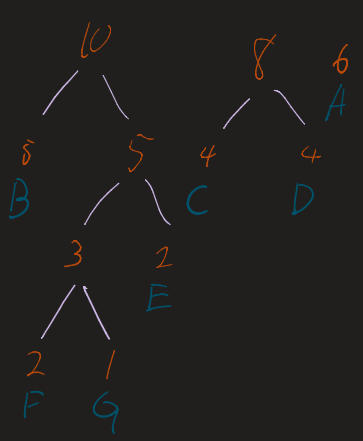
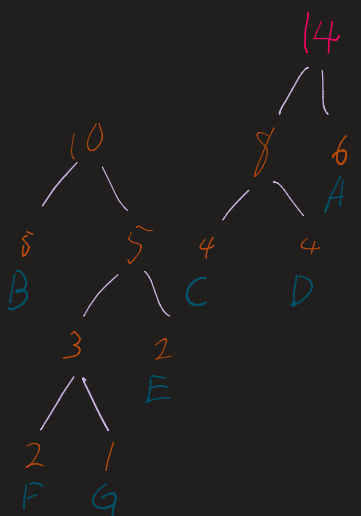
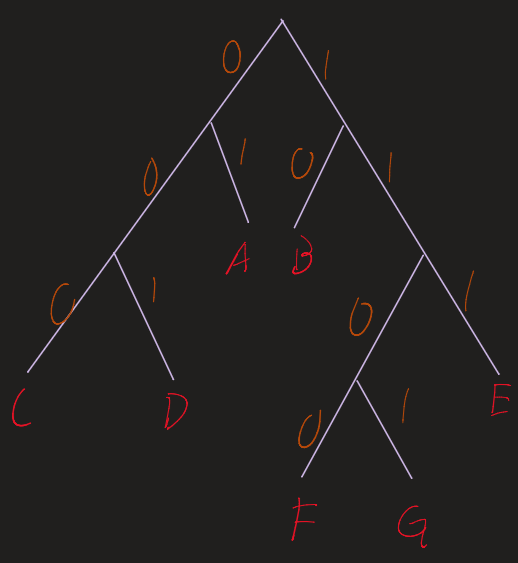
3. Decorate the Tree
Assign a binary value to each edge:
- Left branch =
0 - Right branch =
1
Practical Example Analysis
Given the dataset:
| Character | Frequency |
|---|---|
| A | 6 |
| B | 5 |
| C | 4 |
| D | 4 |
| E | 2 |
| F | 2 |
| G | 1 |
Resulting Codewords
| Letter | Frequency | Huffman Code | Length (bits) |
|---|---|---|---|
| A | 6 | 01 | 2 |
| B | 5 | 10 | 2 |
| C | 4 | 000 | 3 |
| D | 4 | 001 | 3 |
| E | 2 | 111 | 3 |
| F | 2 | 1100 | 4 |
| G | 1 | 1101 | 4 |
Efficiency Comparison: Fixed vs. Variable
For a message containing the 24 characters above:
1. Fixed-Length Analysis
- Alphabet Size: 7 unique characters.
- Bits per Char: bits.
- Total Size: .
2. Huffman Analysis
The size is calculated by
Total Savings: compression over fixed-length.
Decoding Logic
Decoding is efficient because of the Prefix-Free property.
- Start at the root.
- Read the bitstream:
- If
0, move Left. - If
1, move Right.
- If
- When you reach a leaf, output that character.
- Immediately jump back to the root for the very next bit.
Related Notes
- Lossless Encoding – Why prefix-free codes are necessary for perfect reconstruction.
- Fixed Length Character-By-Character Encoding For Strings (Fixed Length CBC) – The non-adaptive alternative.
- Variable Length Character-By-Character Encoding for Strings (Variable Length CBC) – General theory of non-uniform bit lengths.
- Data Structure of Huffman Code – Data Structure for Huffman Coding