Developed in 1955 by Allen Newell, Cliff Shaw, and Herbert A. Simon at RAND Corporation, the linked list is a dynamically-allocated data structure that grows as needed in memory.
Core Components: Nodes
Nodes are individual containers holding a single element, linked via pointers.
- Head Pointer: Global pointer to the first node; primary entry point for traversal.
- Tail Pointer: Global pointer to the last node.
- Access Limitation: Only head and tail have direct access; all other nodes require traversal starting from these points.
Structure Variations
| Feature | Singly-Linked List | Doubly-Linked List |
|---|---|---|
| Pointers per Node | 1 (Points to the next node) | 2 (Points to next and previous) |
| Direction | Unidirectional (Forward only) | Bidirectional (Forward and Backward) |
| Termination | Tail points to NULL | Head.prev and Tail.next point to NULL |
| Illustration | 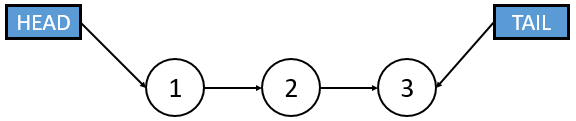 | 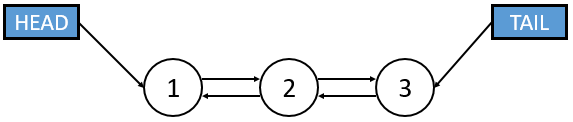 |
If I only have direct access to the head or tail pointer in a Linked List, and I can only access the other elements by following the nodes' pointers, what is the worst-case time complexity of finding an element in a Linked List with elements?
Answer
Operations and Complexity
Searching
Because data is not stored contiguously, random access is impossible. Finding an element requires iterating through nodes one-by-one.
- Worst-Case Complexity: O(n)
- Optimization: In a Doubly-Linked List, if the index is closer to the end, you can start at the tail and traverse backward to save time.
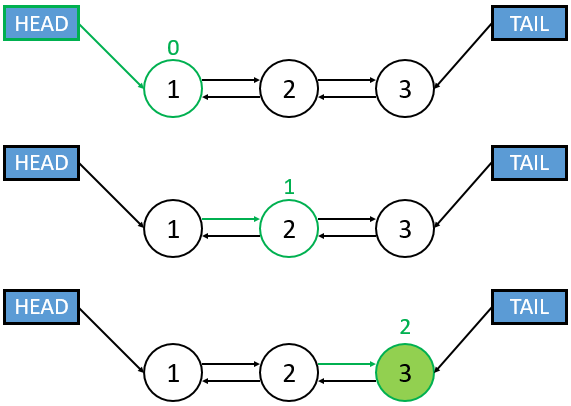
# Search by element
def find(element):
current = head
while current is not NULL:
if current.data == element: return True
current = current.next
return False
# Search by index
def find(index):
if index < 0 or index >= n: return NULL
current = head
for i from 0 to index-1:
current = current.next
return currentNotice that when we look for an element in the middle of the Linked List, we start at the head and step forward. This works fine if the index is towards the beginning of the list, but what about when the index of interest is large (closer to )? Can we speed things up?
Answer
Yes, if the Linked List in question is a doubly-linked list, we can traverse backward instead, having a faster time to get to the element in question
Inserting
- Find Target: Locate the position directly before the insertion index.
- Rearrange Pointers:
- New node’s next → node previously at index i.
- New node’s prev → node before index i.
- Node before index i’s next → New node.
- Node previously at index i’s prev → New node.
| Insertion Point | Complexity | Note |
|---|---|---|
| Head / Tail | O(1) | Direct access via global pointers. |
| Middle | O(n) | Requires traversal to find the site. |
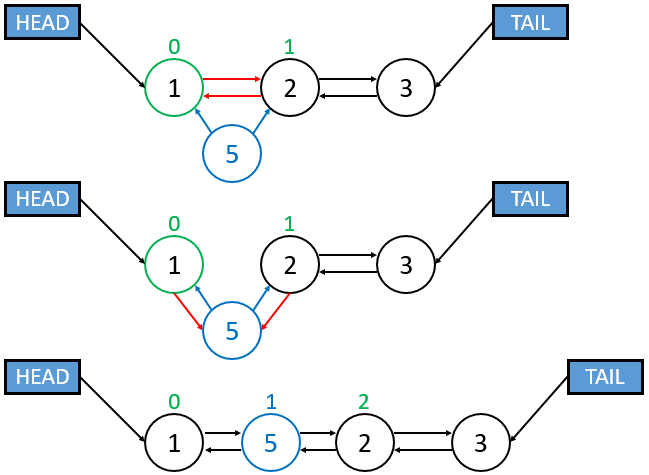
# inserts newnode at position "index" of Linked List
insert(newnode, index):
if index == 0: # special case for insertion at beginning of list
newnode.next = head
head.prev = newnode
head = newnode
else if index == size: # special case for insertion at end of list
newnode.prev = tail
tail.next = newnode
tail = newnode
else: # general case for insertion in middle of list
curr = head
repeat index-1 times: # move curr to directly before insertion site
curr = curr.next
newnode.next = curr.next # update the pointers
newnode.prev = curr
curr.next = newnode
newnode.next.prev = newnode
size = size + 1 # increment sizeRemoval
- Find Target: Locate the node to be removed.
- Rearrange Pointers: Link the surrounding nodes to each other, bypassing the target node.
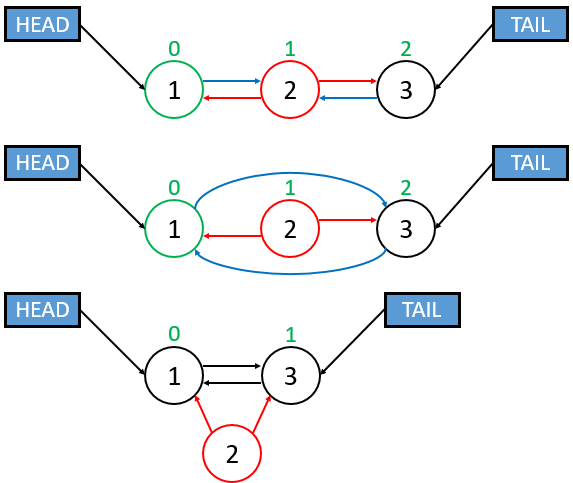
Notice that the node we removed still exists in the diagram. Not considering memory management (only thinking in terms of data structure functionality), is this an issue?
Answer
No, the removed node no longer effects the data structure. It only wastes unnecessary memory space
# removes the element at position "index" of Linked List
remove(index):
if(index == 0): # special case for removing from beginning of list
head = head.next
head.prev = NULL
else if index == n - 1: # special case for removing from end of list
tail = tail.prev
tail.next = NULL
else: # general case for removing from middle of list
curr = head;
repeat index - 1 times: # move curr to directly before removal site
curr = curr.next
curr.next = curr.next.next # update the pointers
curr.next.prev = curr
n = n - 1 # decrement nSummary: Linked Lists vs. Array Lists
| Feature | Linked List | Array List |
|---|---|---|
| Access/Search | O(n) — Sequential only | O(1) Access / O(logn) Search (Sorted) |
| Head Insert/Delete | O(1) — Pointer swap | O(n) — Requires shifting all elements |
| Tail Insert/Delete | O(1) — Pointer swap | O(1) Amortized |
| Memory Usage | Dynamic — No wasted slots | Static/Chunked — Potential wasted space |
| Memory Overhead | Higher — Stores data + pointers | Lower — Stores only data |
Key Takeaways:
- Linked Lists excel at the ends of the list and offer efficient memory growth without pre-allocation.
- Array Lists dominate in search-heavy scenarios and random access.
- Neither strategy is strictly superior; the choice depends on the specific frequency of operations in your application.