ABSTRACT
Data compression and encryption rely on the same fundamental mechanism: a mapping between an original alphabet and a coded alphabet. In computer science, we optimize this mapping using coding trees, where the path from the root to a leaf determines the binary representation of a symbol.
1. The Core Mechanism
Every coding system requires two symmetrical processes:
- Encoding: Converting the original message into a coded format (e.g., text to binary).
- Decoding: Reconstructing the original message from the code.
To perform these tasks efficiently, we need a deterministic way to generate and represent the mapping.
2. Representing Mappings with Coding Trees
A Coding Tree is a visual and computational way to represent how characters are converted into bitstrings (0s and 1s).
How to Read a Coding Tree:
- Edges: Labeled with bits (usually
0for a left branch and1for a right branch). - Leaves: Contain the actual symbols from the original alphabet (e.g., A, C, G, T).
- Path: The code for a symbol is the sequence of labels on the edges from the root to that leaf.
Example
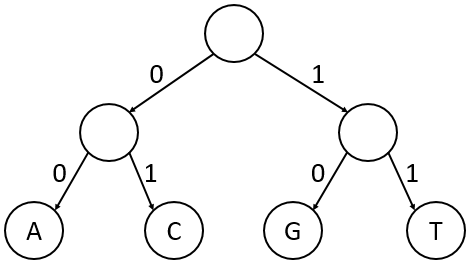
- Path to A: Left → Left = 00
- Path to C: Left → Right = 01
- Path to G: Right → Left = 10
- Path to T: Right → Right = 11
3. Fixed-Length vs. Variable-Length
In the example above, every character is represented by exactly 2 bits. This is known as a Fixed-Length Code.
- Pros: Easy to jump to a specific character in the encoded string.
- Cons: Inefficient if some characters appear much more frequently than others.
Modern compression (like ZIP files or JPEG images) uses Variable-Length Codes, where frequent characters get shorter paths (fewer bits) and rare characters get longer paths.
4. Preview: The Requirements of a Mapping
For a code to be “usable,” it must satisfy certain properties that we will explore in the next sections:
- Uniqueness: A coded message must decode to exactly one original message.
- Prefix Property: No code for a symbol should be a prefix of another symbol’s code (to avoid ambiguity during decoding).
- Optimality: The mapping should minimize the total length of the coded message based on character frequency (the basis of Huffman Coding).